Luckyxyz
首页
归档
关于
友链
切换模式
返回顶部
首页
技术实践
书斋絮语
说点儿什么
Luckyxyz
首页
技术实践
书斋絮语
说点儿什么
首页
归档
关于
友链
【软考】SQL 数据定义语言、数据操纵语言、数据查询语言、表的连接查询
技术实践
·
05-11
Luckyxyz
# SQL 语言 ## SQL Server 数据库的体系结构 SQL Server 数据库的体系结构,是由 视图、基本表、存储文件 三级结构组成。 视图:外模式、基本表:模式、存储文件:内模式 ## SQL 语言分类: 按照用途可以分为: - DDL,数据定义语言,Data Definition Language - DML,数据操纵语言,Data Manipulation Language - DQL,数据查询语言,Data Query Language - DCL,数据控制语言,Data Control Language --- # SQL 数据定义语言 ## 建立数据库: 基本语句: ```sql CREATE DATABASE 数据库名 ``` ## 建立基本表 基本语句: ```sql CREATE TABLE 表名 ( 列名 数据类型, ... -- 其他列名,就一直写 列名数据类型, 直到列名都写完 完整性约束, ... ) ```  ## 表级完整性约束有三种子句: - 主键子句(PRIMARY KEY):实体完整性, - 检查子句(CHECK):用户自定义完整性 - 外键子句(FOREIGN KEY):参照完整性 ## 定义列时使用的基本数据类型: - INTEGER:整数,也可以写成 INT - FLOAT(n):浮点数,精度至少为 n 位数字 - NUMERIC(p,d):定点数,由 p 位数字(不包括符号,小数点)组成,小数点后面有 d 位数字,也可以写成 DECIMAL(p,d) 或 DEC(p,d) - CHAR(n):长度为 n 的定长字符串 - DATETIME:日期时间型 ## 修改基本表结构: 基本表创建完成后,可以根据需要增加列、修改列或者删除列: - 增加一个新列的基本语句: ```sql ALTER TABLE 表名 ADD 列名 类型 ``` - 修改一个新列的基本语句 ```sql ALTER TABLE 表名 ALTER COLUMN 列名 新类型 MY SQL: ALTER TABLE 表名 MODIFY 列名 新类型 ``` - 删除一个列的语句: ```sql ALTER TABLE 表名 DROP COLUMN 列名 ``` 例子: 使用 以下命令建立 test 表: ```sql CREATE TABLE test ( f1 char(10), f2 int ) ``` 以下语句在该表中增加一个 f3 列: ```sql ALTER TABLE test ADD f3 Datetime ``` 以下语句删除 test 表中的 f2 列: ```sql ALTER TABLE test DROP COLUMN f2 MY SQL: ALTER TABLE 表名 DROP f2 ``` ## 删除基本表: 基本语句: ```sql DROP TABLE 表名 ``` --- ## 列级完整性约束 - not null:这一列的值不能为空 - unique:这一列的值是唯一的,可以为空 - not null unique:这一列的值不为空,并且值唯一 - default:默认值 例子: ```sql CREATE TABLE sjk ( a int not null, b int unique, c int not null unique, d char(3) default 'sjk' ) ``` ## 表级完成性约束: 主键子句(PRIMARY KEY),实体完整性,值可以唯一标识呀一个元组 ```sql CREATE TABLE S ( sid int, PRIMARY KEY(sid) -- 这个效果类似于,not null unique,值唯一且不能为空 ) ``` ## 外键元素 外键子句(FOREIGN KEY):参照完整性 ```sql CREATE TABLE R ( cid int, sid int, FOREIGN KEY(sid) REFERENCES S(sid) -- 外键元素的值要参照另外一个表里的元素进行填写,也就是这里的 sid 要参照 S 表中的 sid 进行填写 ) ``` ## 检查子句(CHECK):用户自定义完整性 ```sql CREATE TABLE R ( cid int, sid int, score int, CHECK (score >= 0 AND score <= 100) -- 用户自定义的约束 ) ``` --- # 之后的内容会基于以下例子: ```sql CREATE TABLE student /*学生表*/ ( 学号 CHAR(5) not null unique, 姓名 CHAR(8), 性别 CHAR(2), 出生日期 DATETIME, /*SQL Server 中日期类型 Datetime*/ 班号 CHAR(5) ) CREATE TABLE teacher /*教师表*/ ( 教师编号 CHAR(5) not null unique, 姓名 CHAR(8), 性别 CHAR(2), 出生日期 DATETIME, 职称 CHAR(6), 系别 CHAR(10) /*所在系*/ ) CREATE TABLE course /*课程表*/ ( 课程号 CHAR(5) not null unique, 课程名 CHAR(20), 任课教师编号 CHAR(5) ) CREATE TABLE score /*成绩表*/ ( 学号 CHAR(5), 课程号 CHAR(5), 分数 INT ) ``` # SQL 数据操纵语言 DML ## INSERT 插入语句:向表中添加一下数据: - 直接插入元组:基本语句 ```sql INSERT INTO 表名(列名序列) VALUES (元组值) -- 列名序列是可选的 ``` 或 ```sql INSERT INTO 表名(列名序列) (TABLE (元组值),(元组值),...) ``` - 插入一个查询的结果值 ```sql INSERT INTO 表名(列名序列) SELECT 查询语句 ``` 例子: ```sql INSERT INTO student VALUES('108','张三','男','1998-01-01','09033') ``` 如果只想插入某几列: ```sql INSERT INTO student(学号,姓名,性别,出生日期) VALUES('109','张三','男','1998-01-01') -- 这里的 () 就是表明:可选的,就只插入括号里的这几列 ``` 想要查询数据时: ```sql SELECT 学号,姓名,性别,出生日期,班号 FROM student -- 查询所有,该条命令等价于下面的: SELECT * from student -- * 查询表中的所有列 ``` 插入一个查询的结果值: ```sql INSERT INTO student SELECT '108','张三','男','1998-01-01','09033' ``` ## DELETE 删除语句: 基本语句: ```sql DELETE FROM 表名 [WHERE 条件表达式] -- [] 意思是可选:你可以选择加入一个表达式,也可以不加表达式 ``` 举例: 删除 student 表中 所有班号为 09033 的学生记录: ```sql DELETE FROM student WHERE 班号 = '09033' ``` ## UPDATE 修改语句 基本语句: ```sql UPDATE 表名 SET 列名=值表达式 [,列名=值表达式] -- []也是可选,如果有很多就一直写 [WHERE 条件表达式] ``` 例子: ```sql UPDATE student SET 班号='09033' WHERE 学号='108' -- 意思就是,把学号 108 的这条记录的班号修改成 09033。如果不加 WHERE 条件,就会把所有记录的班号都修改成 09033 UPDATE student SET 班号='09033', 性别='女' WHERE 学号='108' AND 出生日期='1998-01-01' ``` --- # SQL 数据查询语言 DQL 从数据库中查询数据,SQL 数据查询功能是通过 SELECT 语句实现的,SELECT 语句的完整语法如下: ```sql SELECT 目标表的列名或列表达式序列 FROM 关系名表序列 [WHERE 行条件表达式] [GROUP BY 列名序列] [HAVING 组条件表达式] [ORDER BY 列名[ASC|DESC]...] -- 以上的所有中括号意味着可选,就是可以加也可以不加 ``` SELECT 语句中可以是列名、常数、加减乘除的运算符号构成的算数表达式,比如 SELECT 学号,学号 * 100,输出的就是两列:学号、学号 * 100 的结果 使用 DISTINCT 可以保证查询结果集中不存在重复元组 FROM 子句中出现多个基本表(二维表)或者视图时,系统首先执行笛卡尔积操作 WHERE 子句的条件表达是可以使用的运算符有: - 比较运算符:<,<=, >, >=, =,<>(不等于) - BETWEEN 运算符: - 逻辑运算符:AND、OR、NOT - 集合成员运算符:IN、NOT IN - 字符串匹配运算符:LIKE - 谓词:EXISTS、ALL、SOME、UNIQUE - 聚合函数:比较重要 - 空值比较运算符:IS NULL、IS NOT NULL - 集合运算符:UNION、INTERSECT、EXCEPT --- ## 投影查询 SELECT 可以选择查询表中的任意列 ```sql SELECT 姓名,性别,班号 FROM student -- 去掉重复的: SELECT DISTINCT 系别 FROM teacher ``` 改变查询结果中显示的列名:可以在 SELECT 语句的列名后使用 “AS 标题名”。这样在显示时便以改标题名来进行显示新的列名 ```sql SELECT 学号 AS 'SNO', 姓名 AS 'SNAME', 性别 AS 'SEX', 班号 AS 'CLASS' FROM student ``` 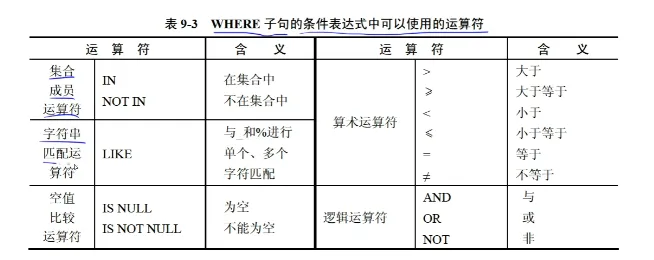 --- ## 选择查询 制定查询条件,只从源表提取满足该查询条件的记录 条件表达式的比较运算: 检索 score 表中成绩在 60-80 之间的所有记录:(闭区间) ```sql SELECT * FROM score WHERE 分数 BETWEEN 60 and 80 -- 等价于 SELECT * FROM score WHERE 分数 >= 60 AND 分数 <= 80 ``` --- ## 字符串的匹配运算: 利用字符串的匹配运算进行模糊查询,谓词 LIKE 可以用来进行字符串的匹配运算: ```sql [NOT] LIKE '匹配串' [ESCAPE '匹配串'] ``` 查找指定的属性列与匹配串线匹配的元组,匹配串可以是一个完整的字符串,也可以是包含有通配符 % 和 _ - % 百分号:代表任意长度(长度可以为 0)的字符串,例如 a%b 表示,以 a 开头,以 b 结尾的任意长度的字符串,比如 acb、addgb、ab 等都满足该匹配串 - _ 下划线:代表任意单个字符,例如 a_b 表示,以 a 开头,以 b 结尾的长度为 3 的任意字符串,acb、afb 等都满足。几个下划线代表几个字符 例: 查找姓王的学生信息: ```sql SELECT * FROM student WHERE 姓名 LIKE '王%' ``` 查找不姓王的学生信息: ```sql SELECT * FROM student WHERE 姓名 NOT LIKE '王%' ``` 比如我要查找课程名以计算机开头的五个字的信息: ```sql SELECT * FROM score WHERE 课程名 LIKE '计算机__' ``` 如果表中有:计算机网络、计算机基础、计算机组成原理,那么会被查询出的是:计算机网络、计算机基础 --- ## 集合的比较运算 包含集合成员运算符: 检索 score 表中成绩为 85/86/88 的记录 ```sql SELECT * FROM score WHERE 分数 IN (85,86,88) ``` --- ## 逻辑组合运算 包含多个条件子句 检索 student 表中 '09031' 班 或性别为 '女' 的学生记录: ```sql SELECT * FROM student WHERE 班号='09031' OR 性别='女' ``` --- ## 排序查询 通过在 SELECT 命令中加入 ORDER BY 子句来控制选择行的显示顺序。 ORDER BY 子句可以按升序(默认,或者 ASC)、降序(DESC)排序各行。也可以按照多个列来排序 其中,ORDER BY 子句必须是 SELECT 命令中的 最后一个子句 例:检索 student 表的所有男生记录,并以班号降序排序 ```sql SELECT 学号, 姓名, 班号 FROM student WHERE 性别 = '男' ORDER BY 班号 DESC ``` 以课程号升序、分数降序检索 score 表中的所有记录: ```sql SELECT * FROM score ORDER BY 课程号, 分数 DESC -- 以课程号为第一基准,如果课程号相同,则以分数为第二基准,降序排列 ``` --- ## 使用聚合函数 聚合函数实现数据统计等功能,用于对一组值进行计算并返回一个单一的值。 聚合函数常与 SELECT 语句的 GROUP BY 子句一起使用 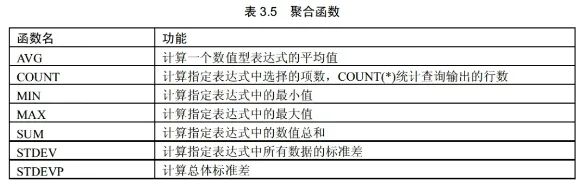 - AVG:平均值 - COUNT:求总数,结果中一共有多少条记录 / 多少元组 - COUNT(* ):统计结果中有多少行 - MIN:最小值 - MAX:最大值 - SUM:数值总和 举例:对分数表中的分数求平均值、有多少元组、最小值、最大值、数值总和、最大值最小值的分差: ```sql SELECT AVG(分数) FROM score SELECT COUNT(*) FROM score -- 有多少行返回多少行 SELECT MIN(分数) FROM score SELECT MAX(分数) FROM score SELECT SUM(分数) FROM score SELECT MAX(分数) - MIN(分数) AS '差值' FROM score ``` 统计有多少课被选修: ```sql SELECT COUNT(DISTINCT(课程号)) FROM score ``` 聚合函数参数的一般格式: ```sql [ALL|DISTINCT] expr ``` - ALL 表示对所有值进行聚合函数运算,是默认值 - DISTINCT 指定每个唯一值都被考虑 - expr 指定进行聚合函数运算的表达式 检索 score 表中 ‘6-166’ 号课程的平均分: ```sql SELECT AVG(分数) AS '6-166课程平均分' FROM score WHERE 课程号='6-166' ``` AVG 不会统计空值 --- ## 数据分组 聚合函数统计的结果是单一的结果,GROUP BY 就是分组,按照指定列进行分组 当聚合函数和 GROUP BY 一起使用时,聚合函数作用于每一个分组 HAVING:可以简单记为:如果条件中包含聚合函数,那么不能用 WHERE 要用 HAVING ## 执行顺序: 当 WHERE 子句、GROUP BY 子句、HAVING 子句 和 聚合函数在同一个查询条件中: - 执行 WHERE 子句,从表中选取行 - 由 GROUP BY 对选取的行进行分组 - 执行聚合函数 - 执行 HAVING 子句选取满足条件的分组 检索 score 中最低分大于 70、最高分小于 90 的学生学号 ```sql SELECT 学号 FROM score WHERE 分数 IS NOT NULL GROUP BY 学号 HAVING MIN(分数) > 70 AND MAX(分数) < 90 ``` 检索 score 表中 最高分与最低分之差大于 12 分的学号: ```sql SELECT 课程号, MAX(分数) AS '最高分', MIN(分数) AS '最低分' from score WHERE 分数 IS NOT NULL GROUP BY 学号 HAVING MAX(分数) - MIN(分数) > 12 ``` --- # 表的连接查询 在一个查询中,当需要对两个或多个表连接时,可以指定连接列,在 WHERE 子句中给出连接条件,在 FROM 子句中指定要连接的表: ```sql SELECT 列名 1, 列名 2, ... FROM 表 1, 表 2, ... WHERE 连接条件 ``` 连接的多个表通常存在公共列,为了区别,在连接条件中通过表名前缀指定连接列,如,“teacher.姓名”、“student.姓名” 内连接:θ 连接、等值连接、自然连接 INNER JOIN ```sql SELECT * FROM student INNER JOIN score on student.'学号' = score.'学号' ``` 等值连接: 查询所有学生的姓名、课程、分数列: ```sql SELECT student.姓名, score.课程, score.分数 FROM student, score WHERE student.学号 = score.学号 ```  外连接: OUTER JOIN
软考
取消回复
提交评论
Luckyxyz
我们谈论生活,讨论技术,借由文字,抵达心灵。
热门文章
Obsidian 迁移全记录(又名:纯小白的闭坑指南)
【Kubernetes】第一个实例 - Java Web 应用
新年新气象,关于年终总结,关于未来展望
使用宝塔面板对网站、数据库等进行定时备份到腾讯云 COS 对象存储
2025 年
在细雨中呼喊,在困顿中挣扎
Ubuntu 22.04 server 安装教程
最新评论
山佳Ellen: 有独到的见地,有个性的思想,精彩!
t: 2026 扬帆起航, 喜迎新年,万象更新, 时间旅行,人间探索,...
tls: 赞一个
lovingchina: 我也准备从Joplin迁移到Obsidian,刚好参考你这一篇哈...
tl.s: 很棒的一本书,可以解答很多人们关于人工智能的疑惑。或许未来怎样谁...
tl.s: 很实用 🦆🦆
tl.s: 绘图很清晰,图示质量很高
热门标签
软考
Kubernetes
读书笔记
Linux
Ubuntu
生活随笔
生活
2025
Python3
Debian
Ansible
空间智能
openFuyao
技术实践
在细雨中呼喊
粤ICP备2024349207号


