Luckyxyz
首页
归档
关于
友链
切换模式
返回顶部
首页
技术实践
书斋絮语
晴天札记
Luckyxyz
首页
技术实践
书斋絮语
晴天札记
首页
归档
关于
友链
【Kubernetes】Service
技术实践
·
2025-03-10
Luckyxyz
# 概述 Service 服务是 Kubernetes 里的核心资源对象之一,Kubernetes 里的每个 Service 其实就是我们经常提到的 **微服务架构** 中的一个 **微服务**。 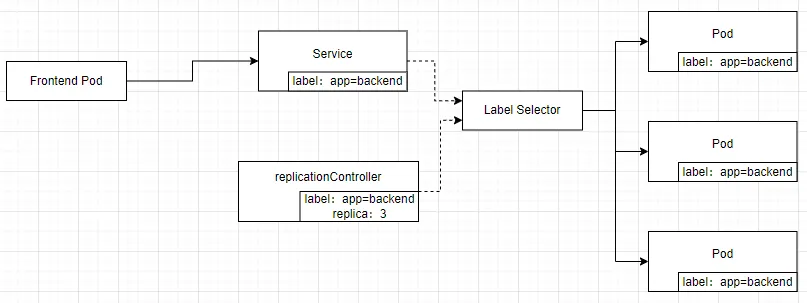 如上图所示: - Kubernetes 的 Service 定义了一个服务的访问入口地址 - 前端的应用(Pod)通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例 - Service 与其后端 Pod 副本集群之间是通过 Label Selector 来实现无缝对接的 - RC 的作用是保证 Service 的服务能力 和 服务质量始终符合预期标准 # 简单来说 Service 是一个联通,一个 Pod 通过 Service 来找到应该对应的另一个 Pod # 网络通信 通过分析、识别并建模系统中的所有服务为微服务 -- Kubernetes Service,系统最终由多个提供不同业务能力而又彼此独立的微服务单元组成,服务之间通过 TCP/IP 进行通信,从而形成了强大而又灵活的弹性网格,拥有强大的分布式能力、弹性伸缩能力、容错能力,程序架构也变得简单和直观 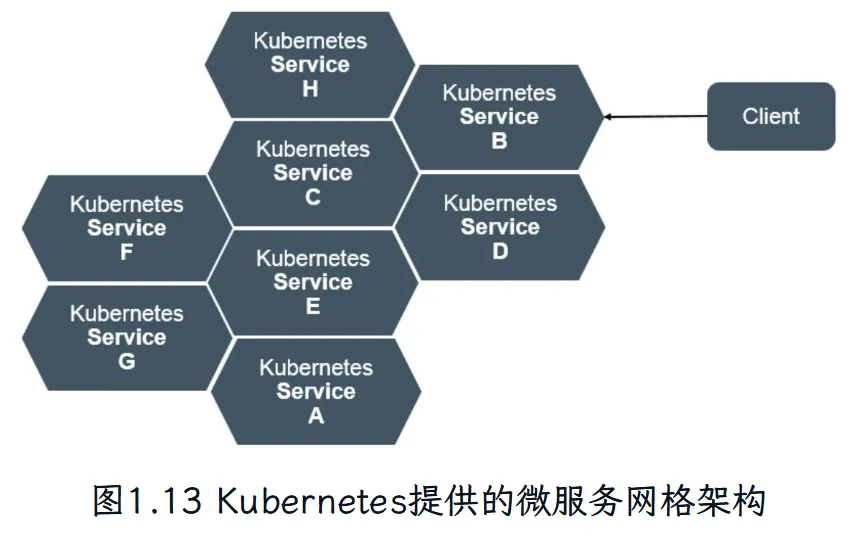 既然每个 Pod 都会被分一个单独的 IP 地址,而且每个 Pod 都提供了一个独立的 Endpoint(Pod IP + ContainerPort)以被客户端访问,多个 Pod 副本组成了一个集群来提供服务。 ↓客户端访问方式↓ 部署一个负载均衡器(软件或硬件),为这组 Pod 开启一个对外的服务端口如 8000 端口,将这些 Pod 的 Endpoint 列表加入 8000 端口的转发列表,客户端就可以通过负载均衡器的对外 IP 地址 + 服务端口 来访问此服务 客户端的请求最后会被转发到哪个 Pod,由负载均衡器的算法所决定。 运行在每个 Node 上的 `kube-proxy` 进程其实就是一个智能的软件负载均衡器,负责对把 Service 的请求转发到后端的某个 Pod 实例上,并在内部实现服务的负载均衡与会话保持机制。 Service 没有共用一个负载均衡器的 IP 地址,每个 Service 都被分配了一个全局唯一的 `虚拟 IP 地址`,这个虚拟 IP 地址被称为 `Cluster IP`。 每个服务就变成了具备唯一 IP 地址的通信节点,服务调用就变成了最基础的 TCP 网络通信问题。 # 服务发现问题 Pod 的 Endpoint 地址会随着 Pod 的销毁和重新创建而发生改变,因为新的 Pod 的 IP 地址与之前旧的 Pod 的不同。 而 Service 一旦被创建,Kubernetes 就会自动为它分配一个可用的 Cluster IP,而在 Service 的整个生命周期内,他的 Cluster IP 不会改变。 只要用 Service 的 Name 与 Service 的 Cluster IP 地址做一个 DNS 域名映射,即可完美解决问题。 # Service 实践 ## 创建 Service 定义文件 ```bash touch tomcat-service.yaml ``` 配置文件内容如下: ```yaml apiVersion: v1 kind: Service metadata: name: tomcat-service spec: ports: - port: 8080 # 服务端口为 8080 selector: tier: frontend # 拥有 “tier=frontend” 这个 Label 的 所有 Pod 实例都属于他 ``` ## 创建 Service ```bash kubectl create -f tomcat-server.yaml ```  在之前的实践中的 `tomcat-deployment.yaml` 里定义的 Tomcat 的 Pod 刚好拥有这个标签,所以刚才创建的 tomcat-service 已经对应一个 Pod 实例了。 ## 查看 tomcat-service 的 Endpoint 列表 ```bash kubectl get endpoints ``` 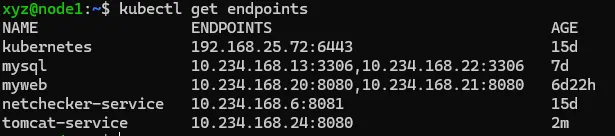 其中 10.234.168.24 是与 `tomcat-service` 关联的 Pod 的 IP 地址,端口 8080 是 Container 暴露的端口。 执行上述命令时,显示的是 Service 对应的后端 Pod 的实际 IP 地址和端口。 工作流如下: 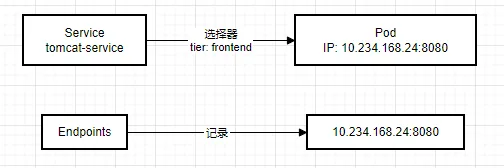 需要了解的是: - 这个 IP 不是 Service 的 Cluster IP; - Service 通过 Endpoints 对象跟踪所有匹配的 Pod IP - kube-proxy 使用这些 Endpoints 信息来设置网络规则 - 当有请求访问 Service 时,会被转发到这些 Endpoints 中的某个 Pod IP ## 查看 Service 的 Cluster IP 执行以下命令(输出详细的 YAML 格式): ```bash kubectl get svc tomcat-service -o yaml ``` 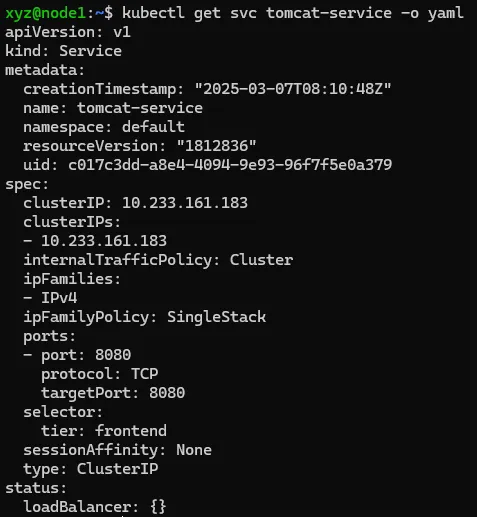 执行以下命令(简洁): ```bash kubectl get service tomcat-service ```  在 `spec.ports` 的定义中, - `targetPort` 属性用来确定提供该服务的容器所暴露(EXPOSE)的端口号,即 具体业务进程在容器内的 targetPort 上提供 TCP/IP 接入 - `port` 属性定义了 Service 的虚端口。 # Service 的多端口问题 很多服务都存在多个端口的问题,通常一个端口提供业务服务,另外一个端口提供管理服务,比如 Mycat、Codis 等常见中间件。 Kubernetes Service 支持多个 Endpoint,在存在多个 Endpoint 的情况下,要求每个 Endpoint 都定义一个名称来区分 多端口的 yaml 文件内容: ```yaml apiVersion: v1 kind: Service metadata: name: tomcat-service spec: ports: - port: 8080 name: service-port - port: 8005 name: shutdown-port selector: tier: frontend ``` # Kubernetes 的服务发现机制 任何分布式系统都会涉及 `服务发现` 这个基础问题,大部分分布式系统都通过提供特定的 API 接口来实现服务发现功能,但这样做会导致平台的侵入性比较强,也增加了开发、测试的难度。Kubernetes 采用比较直观朴素的思路来解决这个问题: 每个 Kubernetes 中的 Service 都有`唯一的` `Cluster IP` 及 `唯一的` `名称`,名称是有开发者自己定义的,部署时也不需要改变,所以完全可以被固定在配置中。 ## 采用 Linux 环境变量解决该问题 每个 Service 都生成一些对应的 Linux 环境(ENV),并在每个 Pod 的容器启动时自动注入这些环境变量. ### 环境变量 #### 环境变量基本概念 - 环境变量就是系统级的 “全局变量” - 他们是以 “键值对” 的形式存在,如 `NAME=VALUE` - 所有运行的程序都可以访问这些变量 #### 在 Kubernetes 中的作用 - 配置应用程序 - 传递服务发现信息 - 存储敏感信息(通过 Secrets) - 传递运行时参数 #### 环境变量的优势 - 配置与代码分离 - 便于管理不同环境(开发、测试、生产) - 提高安全性(敏感信息可以通过环境变量注入) - 便于服务发现和配置 ### 查看 tomcat-service 产生的环境变量条 ```bash kubectl get pods NAME READY STATUS RESTARTS AGE frontend-6f78b7f7b8-f7xjz 1/1 Running 0 26h mysql-4jzdh 1/1 Running 0 2d2h mysql-8n5ss 1/1 Running 0 7d23h myweb-4t4rj 1/1 Running 0 7d myweb-mnlxr 1/1 Running 0 7d netchecker-agent-5wkcf 1/1 Running 0 15d netchecker-agent-hostnet-w2bdc 1/1 Running 0 15d netchecker-server-67c989ccbb-2hfdd 2/2 Running 1 (15d ago) 15d ``` 但是此时,如果我们直接执行查看环境变量的命令是看不到 tomcat service 的环境变量的,因为如果我们顺着实践顺序,当前的 pod 都是在 tomcat service 创建之前创建的 pod。所以我们如果想要查看 tomcat service 的环境变量 需要先创建一个新的 pod 创建 deployment 配置文件 ```bash touch test-deployment.yaml ``` ```yaml apiVersion: apps/v1 kind: Deployment metadata: name: test-deploy spec: replicas: 1 selector: matchLabels: app: test-deploy template: metadata: labels: app: test-deploy spec: containers: - name: busybox image: busybox command: ["sleep", "3600"] ``` 然后执行命令创建 pod ```bash kubectl apply -f test-deployment.yaml ``` 完成创建之后,get pods 找到刚刚创建的 pod 名称:test-deploy-5f8f6c99b6-hrhfs 执行以下命令: ```bash kubectl exec test-deploy-5f8f6c99b6-hrhfs -- env | grep TOMCAT_SERVICE ``` 看到环境变量如下: ```js TOMCAT_SERVICE_PORT_8005_TCP_PROTO=tcp TOMCAT_SERVICE_PORT_8005_TCP_PORT=8005 TOMCAT_SERVICE_SERVICE_PORT_SERVICE_PORT=8080 TOMCAT_SERVICE_PORT_8080_TCP_PORT=8080 TOMCAT_SERVICE_PORT_8005_TCP=tcp://10.233.161.183:8005 TOMCAT_SERVICE_SERVICE_PORT=8080 TOMCAT_SERVICE_PORT_8005_TCP_ADDR=10.233.161.183 TOMCAT_SERVICE_PORT_8080_TCP_PROTO=tcp TOMCAT_SERVICE_PORT_8080_TCP_ADDR=10.233.161.183 TOMCAT_SERVICE_SERVICE_PORT_SHUTDOWN_PORT=8005 TOMCAT_SERVICE_SERVICE_HOST=10.233.161.183 TOMCAT_SERVICE_PORT=tcp://10.233.161.183:8080 TOMCAT_SERVICE_PORT_8080_TCP=tcp://10.233.161.183:8080 ``` #### 最重要的三个环境变量 - `TOMCAT_SERVICE_SERVICE_HOST=10.233.161.183` - Service 的 ClusterIP - 这是服务的主机地址 - `TOMCAT_SERVICE_SERVICE_PORT=8080` - Service 的主端口 - 这是服务的默认端口 - `TOMCAT_SERVICE_PORT=tcp://10.233.161.183:8080` - 完整的服务访问地址 - 组合了协议、IP和端口 这三个被认为最重要是因为: - 它们提供了最基本的连接信息(IP + 端口) - 格式简单直接,易于应用程序使用 - 包含了服务的核心访问信息 ### 服务发现的工作原理 #### 自动注入机制 - 当 Pod 创建时,Kubernetes 会自动注入所有已存在 Service 的环境变量 - 变量命名遵循固定格式:`<SERVICE_NAME>_SERVICE_HOST` 和 `<SERVICE_NAME>_SERVICE_PORT` 但通过环境变量来获取 Service 地址的方式仍然不太方便、不够直观,原因如下: - 环境变量是静态的,创建之后不会更新 - 只能发现 Pod 创建时已存在的服务 后来通过 Add-On 增值包引入了 `DNS 系统`(更加动态),把服务名作为 DNS 域名,这样程序就可以直接使用服务名来建立通信连接了。 # 外部系统访问 Service 的问题 ## Node IP `Node IP` 是 Kubernetes 集群中每个节点的物理网卡的 IP地址,是一个 `真实存在` 的物理网络,所有属于这个网络的服务器都能通过这个网络直接通信,不管其中是否有部分节点不属于这个 Kubernetes 集群。 也就是说,在 Kubernetes 集群之外的节点访问 Kubernetes 集群之间的某个节点或者 TCP/IP 服务时,都必须通过 Node IP 通信。 ## Pod IP `Pod IP` 是每个 Pod 的 IP 地址,他是 Docker Engine 根据 docker0 网桥的 IP 地址段进行分配的,通常是一个虚拟的二层网络。 Kubernetes 要求位于不同 Node 上的 Pod 都能够彼此直接通信,所以 Kubernetes 里一个 Pod 里面的容器访问另一个 Pod 里的容器时,就是通过 `Pod IP` 所在的虚拟二层网络进行通信的,而真实的 TCP/IP 流量是通过 Node IP 所在的物理网卡流出的。 ## Cluster IP 是 Service 的 `Cluster IP` 也是一种虚拟的 IP,但更像一个 “伪造” 的 IP 网络 - Cluster IP 仅仅作用于 Kubernetes Service 这个对象,并由 Kubernetes 管理和分配 IP 地址(来源于 Cluster IP 地址池) - Cluster IP 无法被 Ping,因为没有 “实体网络对象” 来响应 - Cluster IP 只能结合 Service Port 组成一个具体的通信端口,单独的 Cluster IP 不具备 TCP/IP 通信的基础,并且他们属于 Kubernetes 集群的封闭空间,集群外的节点如果要访问这个通信端口,则需要做一些额外的工作 - 在 Kubernetes 集群内,Node IP 网、Pod IP 网与 Cluster IP 网之间的通信,采用的是 Kubernetes 自己设计的一种编程方式的特殊路由规则,与我们熟知的 IP 路由有很大的不同 Service 的 `Cluster IP` 属于 Kubernetes 集群内部的地址,无法在集群外部直接使用这个地址。 我们在开发的业务系统中有一部分服务是要提供给 Kubernetes 集群外部的应用或者用户使用的,比如 Web 端的服务模块(eg. 上面的 tomcat-service),如何实现? ↓↓↓ ## Node Port 以之前的 tomcat-service 为例,在 Service 的定义里做如下的扩展: ```yaml apiVersion: v1 kind: Service metadata: name: tomcat-service spec: type: NodePort ports: - port: 8080 nodePort: 31002 name: service-port selector: tier: frontend ``` 解析: - 这是一个 Kubernetes Service 的定义,使用 NodePort 类型来暴露服务: - `type: NodePort` 表明这个 Service 将在集群的每个节点上开放一个端口,使得服务可以从集群外部访问 - `ports`: - `port: 8080`:Service 在集群内部的端口 - `nodePort: 31002` 在每个节点上开放的外部访问端口(范围必须在 `30000~32767` 之间),也就是 手动指定 tomcat-service 的 NodePort 为 31002,否则 Kubernetes 会自动分配一个可用的端口 - `selector: tier: frontend`:定义了 Service 将会路由流量到哪些 Pod,在这个实践中会选择带有标签 `tier: frontend` 的 Pod `kubectl apply -f `之后,出现以下返回显示  可以通过 `<节点 IP>:<NodePort>` 访问服务了,在本实践中 访问 `http://192.168.25.72:31002` 就可以看到 Tomcat 的欢迎界面了。 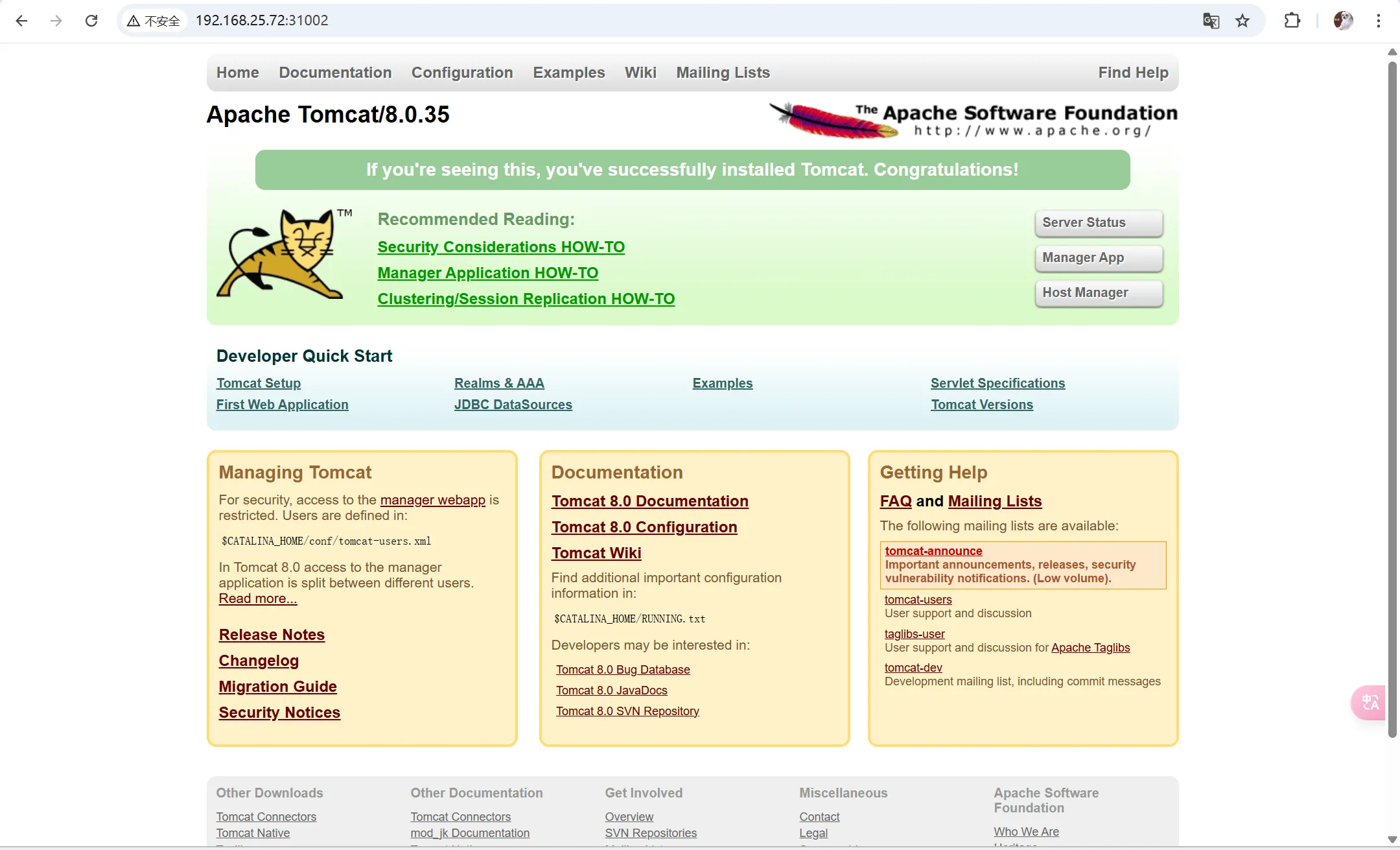 NodePort 的实现方式是在 Kubernetes 集群里的每个 Node 上都为需要外部访问的 Service 开启一个对应的 TCP 监听端口,外部系统只要用任意一个 Node 的 IP 地址 + 具体的 NodePort 端口号即可访问此服务。也就是说 `NodePort Service` 会在所有集群上开放指定端口,所以可以通过任何节点的 IP 加上 NodePort 端口方位服务。 在任意 Node 上运行 `netstat` 命令,就可以看到有 NodePort 端口被监听。需要注意的是,`netstat` 命令需要安装 `net-tools` 包 ```bash sudo apt update sudo apt install net-tools netstat -tlp | grep 31002 ``` 但是经过一系列的排查后,发现仍然无法出现实践实例中的内容,经排查返回以下原因: 1. `curl http://localhost:31002` 失败 - 这是正常的,因为 localhost 可能没有被正确绑定 2. `curl http://node1:31002` 成功 - 返回了完整的 Tomcat 欢迎页面 - 这证明你的 NodePort 服务工作正常 - Tomcat 8.0.35 已经成功部署并可以访问 3. `netstat` 和 `iptables` 没有显示 31002 端口 - 这是因为 Kubernetes 使用了 IPVS 或者其他代理模式 - 这是正常现象,不影响服务的实际使用 ## 解决外部访问 Service 的所有问题 ### 负载均衡问题 假设集群中有 10 个 Node,则此时最好有一个负载均衡器,外部的请求只需要访问此负载均衡器的 IP 地址,由 负载均衡器负责转发流量到后面某个 Node 的 NodePort 上。 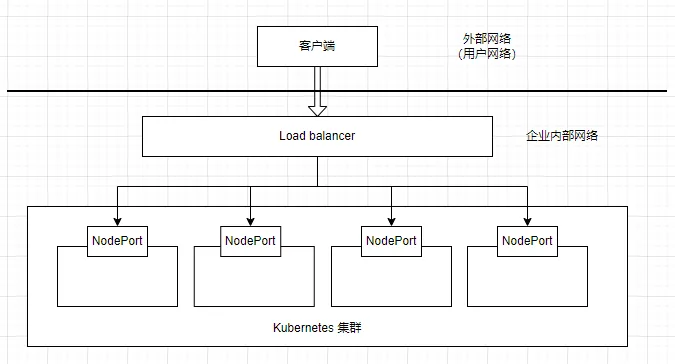 从上图可知,Load balancer 组件独立于 Kubernetes 集群之外,通常是一个硬件的 负载均衡器,或者以软件的方式实现,例如 HAProxy 或者 Nginx。 对于每个 Service 通常需要配置一个对应的 Load balancer 实例来转发流量到后端的 Node 上,但这样会增加工作量及出错的概率。 所以 Kubernetes 提供了自动化的解决方案,如果集群运行在谷歌的 GCE 上,只要讲 Service 的 `type=NodePort` 改为 `type=LoadBalancer`,Kubernetes 就会自动创建一个对应的 Load balancer 实例并返回它的 IP 地址供外部客户端使用。 其他公有云提供商只要实现了支持此特性的驱动,也可以达到上述目的。 裸机上的类似机制(Bare Metal Service Load Balancers)也在被开发。 # 服务暴露、负载均衡、运维管理、高可用、安全、云原生等问题的解决机制 ## 主流云服务商支持 - AWS: 自动创建 ELB/NLB/ALB - Azure: 自动创建 Azure Load Balancer - GCP: 自动创建 Google Cloud Load Balancer - 阿里云: 自动创建 SLB - 腾讯云: 自动创建 CLB ## 新的解决方案 a) **Cloud Controller Manager**: ```yaml apiVersion: v1 kind: Service metadata: name: my-service spec: type: LoadBalancer # 可以指定注解来配置云服务商特定的功能 annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb ``` b) **MetalLB**:为裸机集群提供 LoadBalancer 实现 ```yaml apiVersion: v1 kind: Service metadata: name: my-service spec: type: LoadBalancer # MetalLB 会自动分配 IP ``` ## 新特性 - **服务拓扑** (Service Topology) - **外部流量策略** (External Traffic Policy) - **内部负载均衡器** (Internal Load Balancer) ```yaml metadata: annotations: cloud.google.com/load-balancer-type: "Internal" ``` ## 替代方案 - **Ingress Controller**:更适合 HTTP/HTTPS 流量 - **Service Mesh**:如 Istio,提供更复杂的流量管理 - **Gateway API**:新一代的流量管理 API(目前处于 beta 阶段) 所以基本机制没变,但生态系统更丰富了,选择更多了。根据具体需求,可以: 1. 使用云服务商的 LoadBalancer 2. 在本地环境使用 MetalLB 3. 使用 Ingress 控制器 4. 采用服务网格解决方案 # References - claude 3.5 sonnet - Kubernetes 权威指南:从 Docker 到 Kubernetes 实践全接触(第 4 版)
Kubernetes
取消回复
提交评论
Luckyxyz
我们谈论生活,讨论技术,借由文字,抵达心灵。
热门文章
Obsidian 迁移全记录(又名:纯小白的闭坑指南)
【Kubernetes】第一个实例 - Java Web 应用
新年新气象,关于年终总结,关于未来展望
使用宝塔面板对网站、数据库等进行定时备份到腾讯云 COS 对象存储
2025 年
在细雨中呼喊,在困顿中挣扎
Ubuntu 22.04 server 安装教程
最新评论
t: 2026 扬帆起航, 喜迎新年,万象更新, 时间旅行,人间探索,...
tls: 赞一个
lovingchina: 我也准备从Joplin迁移到Obsidian,刚好参考你这一篇哈...
tl.s: 很棒的一本书,可以解答很多人们关于人工智能的疑惑。或许未来怎样谁...
tl.s: 很实用 🦆🦆
tl.s: 绘图很清晰,图示质量很高
tl.s: 写的很详细,赞👍
热门标签
Kubernetes
读书笔记
Linux
Ubuntu
生活随笔
生活
2025
Python3
Debian
Ansible
空间智能
openFuyao
技术实践
在细雨中呼喊
笔记软件
粤ICP备2024349207号


