Luckyxyz
首页
归档
关于
友链
切换模式
返回顶部
首页
技术实践
书斋絮语
晴天札记
Luckyxyz
首页
技术实践
书斋絮语
晴天札记
首页
归档
关于
友链
【Kubernetes】Horizontal Pod Autoscaler(HPA)
技术实践
·
2025-03-06
Luckyxyz
分布式系统要能够根据当前负载的变化 **自动** 触发水平扩容或缩容,因为这一过程可能是频繁发生的、不可预料的,所以手动控制的方式是不现实的。 HPA 与 RC、Deployment 一样,也属于一种 Kubernetes 资源对象。 # HPA 实现原理 通过追踪分析指定 RC 控制的所有目标 Pod 的负载变化情况,来确定是否需要有针对性地调整目标 Pod 的副本数量。 HPA 有以下两种方式作为 Pod 负载的度量指标: - CPUUtilizationPercentage - 一个算术平均值,即 目标 Pod 所有副本自身的 CPU 利用率的平均值。 - 一个 Pod 自身的 CPU 利用率是该 Pod 当前 CPU 的使用量 除以 它的 Pod Request 的值 - eg. 定义一个 Pod 的 Pod Request = 0.4,当前 Pod 的 CPU 使用量为 0.2,那么它的 CPU 使用率是 50% - 这样可以算出一个 RC 控制的所有 Pod 副本的 CPU 利用率的算术平均值了 - 如果某一时刻 CPUUtilizationPercentage 的值超过 80%,则意味着 当前 Pod 副本数很可能不足以支撑接下来更多请求,需要进行动态扩容 - 在请求高峰时段过去后,Pod 的 CPU 利用率又会降下来,此时对应的 Pod 副本数应该自动减少到一个合理的水平 - 如果目标 Pod 没有定义 Pod Request 的值,则无法使用 CPUUtilizationPercentage 实现 Pod 横向自动扩容 - 应用程序自定义的度量指标,比如服务在每秒内的相应请求数(TPS 或 QPS) # HPA 与其他资源对象 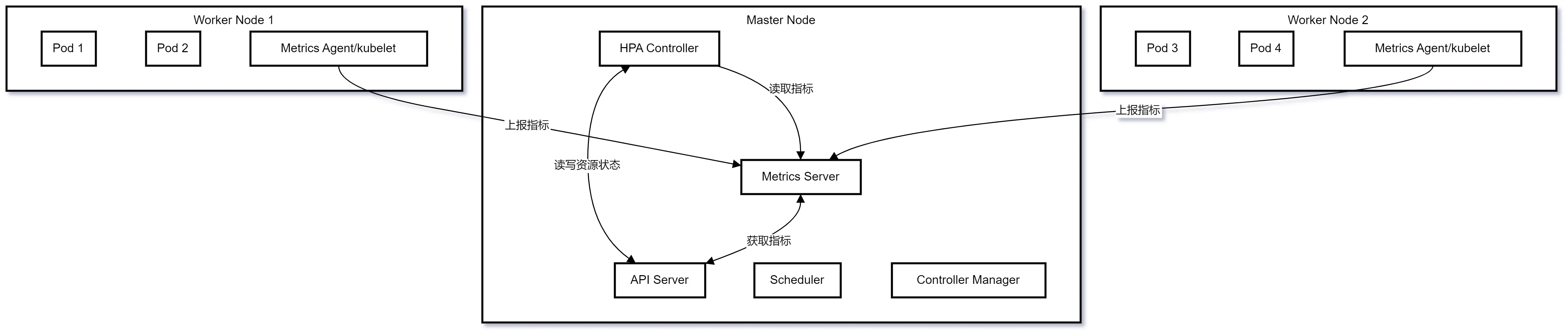 - HPA 是一个自动扩缩容控制器,不直接管理 Pod - HPA 通过监控指标来调整其他控制器(Deployment / RS / RC)的副本数 - 最常见的是与 Deployment 配合使用 - HPA 从 `Metrics Service` 获取监控指标(CPU 使用率、内存使用率等) - 根据设定的目标值计算需要的副本数 - 自动调整目标控制器(如 Deployment)的 replicas 字段 ```txt HPA ↓ (控制副本数) Deployment ↓ (创建和管理) ReplicaSet ↓ (确保副本数量) Pod ``` - HPA 是 `“声明式”` 的,定义 `“期望状态”` - 支持自定义指标和多指标策略 - 可以设置最小和最大副本数限制 - 有 冷却时间机制,防止频繁扩缩容 # HPA 实践 以之前的 deployment 作为延续,先创建一个 HPA 的配置文件 ```bash touch frontend-hpa.yaml ``` 将以下内容写入配置文件: ```yaml apiVersion: autoscaling/v2 # 指定 API 版本,v2 支持多个指标和更复杂的缩放规则 kind: HorizontalPodAutoscaler # 资源类型为 HorizontalPodAutoscaler mietadata: name: frontend-hpa # HPA 资源的名称 spec: # 指定要控制的目标资源 scaleTargetRef: apiVersion: apps/v1 # 目标资源的 API 版本 kind: Deployment # 目标资源类型 name: frontend # 目标 Deployment 的名称 minReplicas: 1 # 最小副本数,即使负载很低也不会低于这个数 maxReplicas: 3 # 最大副本数,即使负载很高也不会超过这个数 metrics: # 指标配置数组,可以配置多个指标 - type: Resource # 指标类型为资源指标 resource: name: cpu # 监控 CPU 资源 target: type: Utilization # 使用率类型 averageUtilization: 50 # 目标使用率为 50% ``` 工作流程如下: 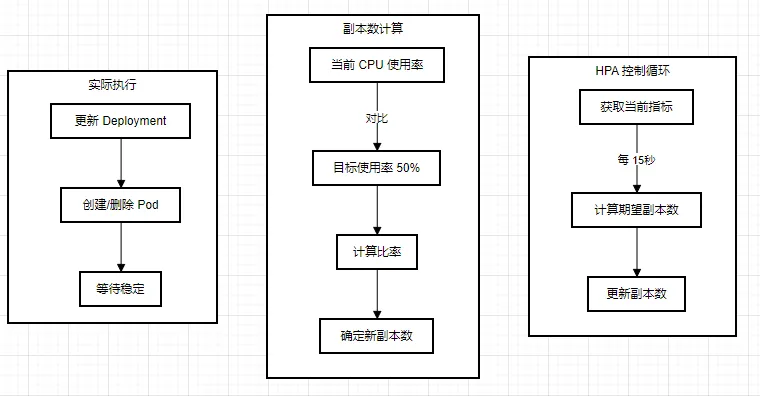 ## 应用配置到集群 创建 HPA: ```bash kubectl apply -f hpa.yaml ```  验证创建结果: ```bash kubectl get hpa ```  发现 `<unknown>` 检查 frontend deploymen 的资源配置: ```bash kubectl get deployment frontend -o yaml | grep -A 8 resources ``` 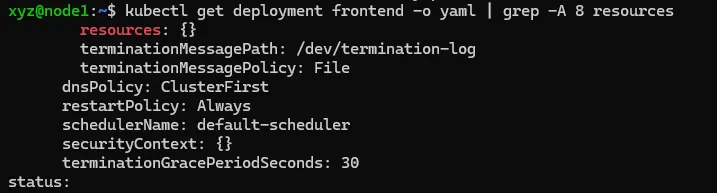 发现是 frontend deployment 没有设置资源请求 `resources: {}` ,所以需要更新 deployment 来添加资源请求: ```bash kubectl patch deployment frontend -p '{ "spec": { "template":{ "spec":{ "containers":[{ "name": "frontend", "resources": { "requests":{ "cpu": "200m", "memory": "256Mi" }, "limits": { "cpu": "500m", "memory": "512Mi" } } }] } } } }' ``` 或者可以直接编辑 deployment 的配置文件: ```yaml // ... existing code ... spec: containers: - name: frontend image: your-image:tag resources: requests: cpu: "200m" memory: "256Mi" limits: cpu: "500m" memory: "512Mi" // ... existing code ... ``` 修改完配置文件后,使用以下命令应用更新: ```bash kubectl apply -f frontend-deployment.yaml ``` 执行 `kubectl get hpa` 可发现问题解决:  # Pod、副本 和 CPU 利用率的关系  ## Pod 副本 - 通过 Deployment 创建的所有 Pod 都是副本 - 他们运行相同的容器镜像和配置 - 每个 Pod 都是完全等价的 ## CPU 利用率计算 单个 Pod 的 CPU 利用率 = 实际 CPU 使用量 / Pod 请求的 CPU 资源量 ## 举例 ```yaml # Deployment 配置 apiVersion: apps/v1 kind: Deployment metadata: name: my-deployment spec: replicas: 3 template: spec: containers: - name: app resources: requests: cpu: "200m" # 请求 0.2 核 CPU ``` ### 初始状态 ```txt Pod-1: 使用 160m CPU / 请求 200m = 80% 利用率 Pod-2: 使用 140m CPU / 请求 200m = 70% 利用率 Pod-3: 使用 180m CPU / 请求 200m = 90% 利用率 平均利用率 = (80% + 70% + 90%) / 3 = 80% ``` ### HPA 决策过程 ```yaml # HPA 配置中的目标利用率为 50% averageUtilization: 50 # 当前平均利用率为 80% # 需要扩容:80% / 50% = 1.6 # 新副本数 = 当前副本数 * 1.6 = 3 * 1.6 ≈ 5 ``` ### 扩容后 ```txt Pod-1: 使用 100m CPU / 请求 200m = 50% 利用率 Pod-2: 使用 90m CPU / 请求 200m = 45% 利用率 Pod-3: 使用 110m CPU / 请求 200m = 55% 利用率 Pod-4: 使用 95m CPU / 请求 200m = 47.5% 利用率 Pod-5: 使用 105m CPU / 请求 200m = 52.5% 利用率 新的平均利用率 = 50% ``` ### 资源请求非常重要 ```yaml containers: - name: app resources: requests: cpu: "200m" # 这个值是计算利用率的基准 ``` ### 监控数据 ```bash # 查看 Pod 的资源使用情况 kubectl top pods NAME CPU(cores) MEMORY(bytes) my-deployment-xxx-pod1 160m 256Mi my-deployment-xxx-pod2 140m 256Mi my-deployment-xxx-pod3 180m 256Mi ``` ### HPA 状态 ```bash kubectl describe hpa example-hpa Name: example-hpa Reference: Deployment/my-deployment Metrics: ( current / target ) resource cpu: 80% / 50% Min replicas: 1 Max replicas: 10 Current replicas: 3 Desired replicas: 5 ``` 总的来说: - Deployment 创建的所有 Pod 都是等价的副本 - HPA 监控所有这些 Pod 的 CPU 利用率 - 利用率是基于每个 Pod 的 CPU 请求量来计算的 - HPA 使用所有 Pod 的平均利用率来做决策 # References - claude 3.5 sonnet - Kubernetes 权威指南:从 Docker 到 Kubernetes 实践全接触(第 4 版)
Kubernetes
取消回复
提交评论
Luckyxyz
我们谈论生活,讨论技术,借由文字,抵达心灵。
热门文章
Obsidian 迁移全记录(又名:纯小白的闭坑指南)
【Kubernetes】第一个实例 - Java Web 应用
新年新气象,关于年终总结,关于未来展望
使用宝塔面板对网站、数据库等进行定时备份到腾讯云 COS 对象存储
2025 年
在细雨中呼喊,在困顿中挣扎
Ubuntu 22.04 server 安装教程
最新评论
t: 2026 扬帆起航, 喜迎新年,万象更新, 时间旅行,人间探索,...
tls: 赞一个
lovingchina: 我也准备从Joplin迁移到Obsidian,刚好参考你这一篇哈...
tl.s: 很棒的一本书,可以解答很多人们关于人工智能的疑惑。或许未来怎样谁...
tl.s: 很实用 🦆🦆
tl.s: 绘图很清晰,图示质量很高
tl.s: 写的很详细,赞👍
热门标签
Kubernetes
读书笔记
Linux
Ubuntu
生活随笔
生活
2025
Python3
Debian
Ansible
空间智能
openFuyao
技术实践
在细雨中呼喊
笔记软件
粤ICP备2024349207号


